Elasticsearch
Elasticsearch란?
-
Apache Lucene(아파치 루씬) 기반의 Java 오픈소스 분산 검색 엔진
- 루씬 : Java 기반 정보 검색 라이브러리 오픈소스 SW
-
방대한 양의 데이터를 신속하게, 거의 실시간(NRT; Near Real Time)으로 저장, 검색, 분석할 수 있다.
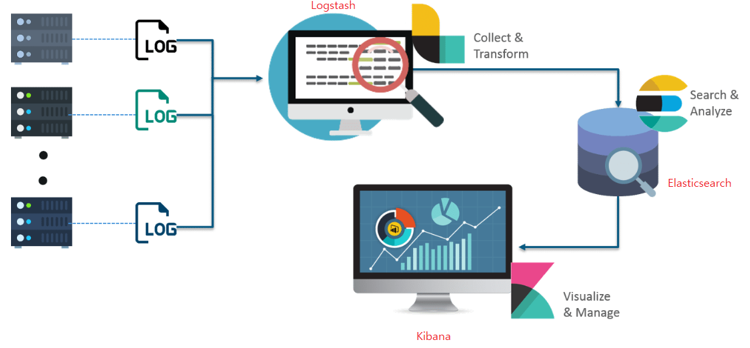
ELK 스택
Elasticsearch는 검색을 위해 단독으로 사용되기도 하며,
ELK(Elasticsearch / Logstatsh / Kibana) 스택(연동 솔루션)으로도 사용한다.
-
Logstash : 다양한 소스(DB, csv 파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달
-
Elasticsearch : Logstash로부터 전달받은 데이터를 검색 및 집계하여 필요한 관심정보 획득
-
Kibana : Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
Why Elasticsearch?
-
RDBMS는 단순 텍스트매칭에 대한 검색만을 제공
-
텍스트를 여러 단어로 변형하거나 동의어, 유의어를 활용한 검색 가능
-
RDBMS에서 불가능한 비정형 데이터의 색인과 검색 가능 -> 빅데이터 처리에서 중요시하는 부분
-
형태소 분석을 통한 자연어 처리 가능(플러그인 제공)
-
역색인 지원으로 매우 빠른 검색 가능
RDBMS 비교
| Elasticsearch | RDBMS |
|---|---|
| Index(데이터가 저장되는 공간, 소문자) | Database |
| Shard(인덱스 내부에 존재하는 부분) | Partition |
| Type | Table |
| Document(ES 데이터의 최소 단위, JSON Object 하나) | Row |
| Field | Column |
| Mapping | Schema |
| Query DSL | SQL |
RESTful API 사용
RDBMS와 Elasticsearch의 데이터 CRUD 방식에 차이가 있다.
RDBMS의 경우 클라이언트에서 관계형DB가 있는 서버에 연결을 맺어 SQL을 날리는 방식이라면,
Elasticsearch의 경우 RESTful API를 방식으로 데이터를 CRUD한다.
POST, 즉 데이터 삽입의 경우 스키마가 미리 정의되어있지 않더라도 자동으로 필드를 생성하고 저장한다.
큰 유연성을 제공하는 특징이지만 선호되는 방법은 아니다.
Elasticsearch 장점
-
데이터베이스 대용으로 사용 가능
-
대량의 비정형 데이터 보관 및 검색 가능
-
기존 DB로 처리하기 어려운 대량의 비정형 데이터 검색 가능
-
전문검색(Full-Text Search)과 구조검색 모두 지원
-
기본적으로는 검색엔진이지만 MongoDB나 Hbase처럼 대용량 스토리지로 사용 가능
-
-
오픈소스 검색엔진
- 아파치 루씬 기반 오픈소스 검색엔진으로 무료 사용 가능, 빠른 버그 해결
-
전문검색(Full-Text Search)
- 내용 전체를 색인하여 특정 단어가 포함된 문서 검색 가능
-
통계 분석
-
비정형 로그 데이터 수집, 통계 분석 가능
-
Kibana를 이용하면 시각화까지 가능
-
-
Schemaless
-
RDBMS는 스키마라는 구조에 따라 데이터를 적합한 형태로 변경하여 저장, 관리
-
Elasticsearch는 비정형의 다양한 형태의 문서도 자동으로 색인, 검색 가능
-
-
RESTful API
- RESTful API를 사용하여 HTTP통신 기반으로 요청을 받아 JSON 형식으로 응답한다는 것은 다양한 플랫폼에서 응용 가능하다는 것을 의미함
-
Multi-tenancy
- 서로 다른 인덱스(RDBMS에서 DB와 같은 개념)에서도 검색할 필드명만 같으면 여러 개의 인덱스를 한 번에 조회할 수 있다.
-
Document-Oriented
-
여러 계층의 데이터를 JSON 형식의 구조화된 문서로 인덱스에 저장 가능
-
계층 구조로 된 문서를 한 번의 쿼리로 쉽게 조회 가능
-
-
Inverted-Index
- 역색인 지원
-
확장성과 가용성
-
대량의 데이터를 분산 시스템 구성으로 병렬적인 처리 가능
-
분산 환경에서는 데이터가 Shard 단위로 나누어 제공됨
-
인덱스 생성 시마다 샤드 수 조정 가능
-
데이터의 종류와 성격에 따라 데이터를 분산하여 빠른 처리 가능
-
Elasticsearch 약점
-
실시간(Real Time) 처리 불가
-
데이터 색인(내부적으로 커밋과 플러시 같은 과정 거침)의 특징 때문에 1초 뒤에나 검색이 가능하다.
-
따라서 실시간 처리는 아니고, NRT(Near Real Time)이 적합하다.
-
-
트랜잭션, 롤백 등의 기능을 미제공
-
데이터 Update 시 실제로는 데이터를 삭제했다가 다시 생성하는 과정으로 Update 진행
Elasticsearch 주요 API
-
인덱스 관리 API (Indices API)
-
문서 관리 API (Document API)
-
검색 API (Search API)
-
집계 API(Aggregation API)
모든 API는 HTTP통신을 이용하여 RESTful하게 사용 가능하다.